
Sinds de introductie van ChatGPT in November 2022 hebben grote taalmodellen ons leven voorgoed veranderd. AI-applicaties zoals ChatGPT en Google Gemini worden steeds vaker gebruikt voor taken als het samenvatten van artikelen en het vertalen van teksten.
Toch merk ik dat relatief weinig mensen weten hoe grote taalmodellen (Large Language Models) werken. Dat is jammer! Doordat je weet hoe deze modellen (ongeveer) werken ga je inzien voor welke taken je ze goed kunt inzetten, en nog veel belangrijker: voor welke taken je ze beter niet kunt gebruiken.
Verschil tussen Generatieve AI en traditionele AI
Artificiële Intelligentie is een term die in 1956 voor het eerst is genoemd. In de twintigste eeuw zijn er vele AI-modellen ontwikkeld, en die ga ik vanaf nu allemaal “traditionele AI” noemen. Als je generatieve AI vergelijkt met traditionele AI is een van de grootste verschillen dat de traditionele AI-modellen worden gebruikt voor hele specifieke taken.
Je kan er bijvoorbeeld huizenprijzen mee voorspellen. Als je de postcode, kavelgrootte en het woonoppervlak gebruikt is het voor zo’n AI-model vrij simpel om een (accurate) prijs voor een huis te voorspellen.
Traditionele AI werd dus steeds voor een heel klein toepassingsgebied gebruikt, en misschien daardoor hadden deze modellen (vergeleken met Generatieve AI) minder trainingsdata nodig, en kunnen ze toch redelijk accurate voorspellingen doen.
Introductie van het transformer model
Artificiële Intelligentie is er dus al heel lang. De dominante techniek om computers iets te “leren” noemen we Machine Learning. En binnen machine learning is er een categorie die Large Language Models heet, oftewel grote taalmodellen. Ook grote taalmodellen waren er al voor de introductie van generatieve AI.
In 2017 werd er door Vaswani et al. het paper “Attention is all you need” uitgebracht. Dit team was een onderzoeksteam van Google en introduceerde een nieuw model, het “transformer” model. Deze paper wordt door velen gezien als de geboorte van generatieve AI.
Een jaar later werd door OpenAI een nieuw paper uitgebracht dat een verbeterde versie van het transformer model introduceerde: De Generative Pretrained Transformer (oftewel GPT).
Alle modellen die momenteel populair zijn, zoals de modellen van Gemini en Anthropic vallen onder de categorie transformer modellen.
Laten we nog even teruggaan naar 2017. Want de werking van het transformer model is redelijk simpel. Waarschijnlijk weet je al dat computers erg goed kunnen rekenen. Ze kunnen miljoenen berekeningen per seconde uitvoeren. Maar tot nu toe “begrepen” computers de data die zij verwerkte niet. Jij gebruikt je computer nu om dit artikel te lezen, maar de computer “begrijpt” de tekst niet.
Dus om computers hun grote talent (rekenen) te laten gebruiken voor het begrijpen van taal moest er een oplossing worden bedacht: tokens.
Tokens zijn stukjes tekst die ongeveer (in werkelijkheid zijn ze iets kleiner) gelijk zijn aan een woord. Je kunt zelf zien hoe modellen zoals ChatGPT jouw tekst omzetten naar tokens op deze website van OpenAI.

Als je op deze website op “Token IDs” klikt, kun je zien dat er aan elke token een uniek getal wordt gekoppeld:
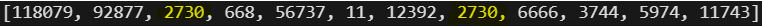
De token ” ik” (de spatie is onderdeel van de token) komt twee keer voor. Dit is dus token 2730. Het token ID (dus het unieke nummer) is niet van belang, maar nu we elke token een uniek cijfer hebben hebben gegeven kunnen we daar relaties tussen bepalen. Dat doen we door vector berekeningen uit te voeren over heel veel combinaties van woorden.
Tokens genereren
Transformer modellen kunnen eigenlijk maar één ding: ze kunnen steeds één token voorspellen die op basis van hun trainingsdata in deze zin past.
Maar de meeste gebruikers willen natuurlijk niet maar één woord (token) voorspellen. Ze willen complete teksten laten schrijven door ChatGPT. In dat geval wordt het GPT-model meerdere keren achter elkaar getriggerd. Wil je een tekst van 400 woorden schrijven? Dan wordt het GPT-model ongeveer 400 keer gestart.
Als voorbeeld geven we de volgende invoer in het model “vandaag voel ik mij”. Bij de eerst run is de output “ziek”. Vervolgens wordt “ziek” toegevoegd aan de input voor het genereren van de volgende token (dus).

De eerste generaties GPT-modellen van OpenAI (GPT-1 en GPT-2) werkten ongeveer zo. Vanaf GPT-3 worden de modellen getraind op conversaties, waardoor hun antwoorden meer zijn gaan lijken op hoe mensen gesprekken voeren.
Aandacht (attention) is alles dat je nodig hebt
Een van de technieken die in het paper van 2017 geïntroduceerd werden, en die transformer modellen zo effectief maken is het attention mechanisme: ook wel Self-Attention of masked multi-head attention genoemd. Deze techniek zorgt ervoor dat het model zijn aandacht kan focussen op bepaalde woorden in een zin die erg belangrijk zijn voor de semantische betekenis.
Knowledge cut-off
Het trainen van een GPT-model kost enkele maanden. GPT-modellen worden getraind op duizenden videokaarten en dit is erg duur en kost veel energie. De knowledge cutoff van GPT-4 is 1 December 2023. Dit betekent dat het model geen kennis heeft van gebeurtenissen die zich hebben afgespeeld vanaf December 2023. GPT-4 weet dus niet dat Donald Trump vanaf 20 Januari 2025 de nieuwe president van de Verenigde Staten is.
Er zijn ook mensen die ChatGPT vragen naar de temperatuur van vandaag. Aangezien GPT-4 jaren geleden getraind is, kan ChatGPT dit toch nooit weten?
Verschil tussen ChatGPT en GPT-modellen
Wanneer je vraagt wie er vanaf 2025 president van de Verenigde Staten is of wat de temperatuur vandaag in Amsterdam is, krijg je toch een (goed) antwoord. Hoe kan dat dan?
Om dit te begrijpen is het goed om te weten dat er een verschil is tussen het GPT-model (bijvoorbeeld GPT-4 of GPT-5) en de applicatie ChatGPT. ChatGPT is een applicatie die je in staat stelt om met een GPT-model te chatten. Naast dat het jou als gebruiker in staat stelt om met een GPT-model te chatten bevat het nog veel meer functionaliteit.
ChatGPT maakt gebruik van technieken zoals Retrieval Augmented Generation en tool calling om vragen te beantwoorden over evenementen die na de knowledge-cutoff van het model zijn gebeurd. Klik op de links om meer over deze technieken te weten te komen.
Gesprekken voeren met een GPT-model
Een GPT-model kan dus maar één ding. Elke keer een token genereren. Maar deze modellen hebben geen geheugen. Hoe kan het model dan jouw conversatie “onthouden”?
Het onthouden van een gesprek gebeurt in de applicatie om het GPT-model heen (ChatGPT dus). Het model krijgt steeds de hele conversatie te zien, zodat het model de complete context begrijpt. Dat gaat zo:
Wanneer je jouw eerste vraag aan ChatGPT stelt, is dit wat ChatGPT naar het GPT-model stuurt:
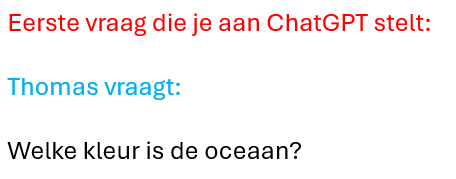
Het GPT-model begint tokens te genereren, en deze worden via ChatGPT weergegeven in jouw webbrowser. Waarschijnlijk krijg je te zien dat de oceaan blauw is.
Laten we nu een vervolgvraag stellen “Hoe diep is hij dan?” Hiervoor moet het GPT-model de eerdere conversatie kunnen zien, anders weet hij simpelweg niet waar “hij” naar refereert.
De hele conversatie is opgeslagen in het geheugen van ChatGPT, en ChatGPT stuurt deze nu naar het GPT-model. Dat ziet er ongeveer zo uit:

Conclusie
Ik hoop met dit artikel iets van de “magie” van ChatGPT te ontrafelen. Want Artificiële Intelligentie is geen magie, maar gewoon techniek en heel veel wiskunde. Ik ben ervan overtuigd dat deze technologie de wereld zoals wij die kennen in de komende jaren op zijn kop gaat zetten. Maar laten we alsjeblieft niet doen alsof deze techniek slim of zelfbewust is. Ik sluit niet uit dat AI-modellen ooit echte intelligentie en misschien zelfs bewustzijn kunnen ontwikkelen. Maar op dit moment zijn ze geen van beiden.


